Fixing Access Forbidden (403) issues after migrating WordPress to a static site
After migrating a WordPress site to static files, Google Search Console may start sending you notifications about page indexing problems. Often the issue will be marked as ‘Blocked due to access forbidden (403)‘, a fairly common error that can have different causes, depending on how your website and server is set up.

This article specifically deals with the case when:
- You previously had a working WordPress installation;
- You migrate the site to static HTML files on an Apache web server;
- Google Search Console starts complaining about page indexing problems.
If this does not apply to your situation, the proposed solution may not work but you will still find the explanation useful in diagnosing the problem.
Table of contents
The Forbidden 403 error
Being in the 4XX category of HTTP response codes, Access Forbidden (403) is a client-side error that may show in a message similar to the following combinations:
- Access Forbidden (403)
- 403 Forbidden
- HTTP 403
- HTTP Error 403 – Forbidden
- Forbidden: You don’t have permission to access [directory path] on this server
The Google Search Console notification email will be about page indexing problems with ‘Blocked due to access forbidden (403)‘ as one of the Top Issues.
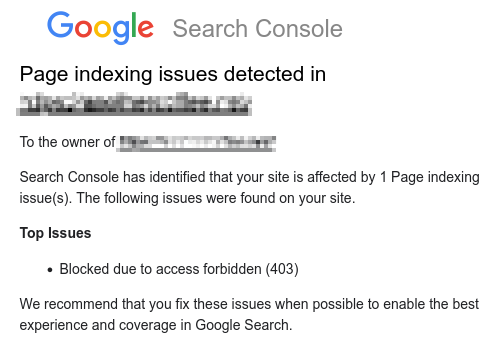
Nevertheless, it being a client-side error doesn’t necessary isolate the problem to your browser. Many solutions online will advise you to clear your cache or refresh the page. This is easy to do and usually a sensible first step but if you found the issue via a Google Search Console notification after a WordPress migration, these recommendations won’t help.
The 403 response code essentially means that a web client, such as your browser, does not have permission to access the requested resource. The web server understands the request but can’t allow access due to file permissions settings or a server misconfiguration. When it comes to WordPress, the error will almost certainly be due to a misbehaving plugin, a corrupt .htaccess file or incorrect file permissions. However, if you’ve recently converted your WordPress installation to a static site, the error will most likely have a different cause.
To understand why the Access Forbidden error happens, it’s worth reviewing the differences between how the WordPress content management system (CMS) serves content and how a static site responds to web client requests.
How WordPress serves your browser requests
WordPress is a database-driven Content management system (CMS). Most of the content is stored in a database and URLs generally do not correspond to any files in the web server’s filesystem. Instead, URLs are external references to the database content. WordPress calls these references permalinks and its rewriting engine uses internal rules, specified in the permalink settings, to build permalinks dynamically. When a client requests a page from the site, WordPress takes care of serving the correct content. Included with the pages will be any XML-based RSS (Really Simple Syndication) feeds. WordPress will send the HTML page or an XML feed, depending on what the client requests.
For example, if you set the permalink settings to the Post name structure, WordPress will generate a HTML post when you browse to the following URL:https://example.com/your-post/
The RSS feed for that post will be at:https://example.com/your-post/feed/
RSS feeds are normally parsed by an RSS client rather than for displaying directly in the browser window so requesting the RSS feed resource will not send HTML. Instead WordPress will generate XML for the feed.
Serving static files
By definition, static sites have no way of dynamically generating content based on the browser request. You make a request to the web server at a given URL and if the resource is present with the correct access permissions, the web server will go ahead and serve the file. The URL for a static site will normally look something like:https://example.com/your-post.html.
If you have an RSS feed, it might look something like:https://example.com/feed.xml.
Notice that the request includes the path to the file, such as your-post.html or feed.xml. The file is not present in a WordPress permalink because, as mentioned previously, it is only a reference to the actual content stored in the database.
Web server directory index
Web servers such as Apache also have a Directory Index directive. This is a configuration that can set the server to automatically send a file when a client makes a request without a filename in the URL. The file known as the directory index and is normally named index.html.
Web servers such as Apache also have a Directory Index directive. In the early days of the web, you could browse to a folder in the web server filesystem and get a listing of all the files present. For security, most web hosts now disable this feature for most of their hosting services. The Directory Index directive is a configuration that can set the server to automatically send a file when a client request only includes the folder name in the URL. For most hosting services, the standard directory index files are normally index.html and index.php.
Say a client makes a request for the following:https://example.com/docs/
If the directory index is set to index.html, the server would return:http://example.com/docs/index.html.
The index.html renders as a web page in the browser. Directory index resources can also be set to other file types like index.txt or index.xml.
Generating static HTML files from a WordPress site
WordPress plugins such as Simply Static will crawl your site to generate static HTML file copies for the pages. Since WordPress includes RSS feeds, static XML copies will also be generated for these feeds. The tables below show typical WordPress permalinks and their equivalents after static HTML copies are generated.
| Page type | WordPress permalink |
|---|---|
| Page content |
|
| RSS feed |
|
| Page type | Static file URL |
|---|---|
| Page content |
|
| RSS feed |
|
Once again notice that the static site specifies the filename in the path whereas the WordPress permalink, when set to the Post name structure, does not.
Why access is forbidden
We have all the puzzle pieces to understand why you would get the Access Forbidden (403) error and how you can fix the problem. After you migrate your WordPress site to static files, the old permalink paths to pages will still serve a web page because most hosting providers have index.html as a directory index resource.
You can request the URL in the WordPress post name permalink format:https://example.com/your-post/
The static file generator would have created an index.html in this location:https://example.com/your-post/index.html
The webserver sees the index.html in the filesystem and delivers it to the browser which can render the web page content. Human site visitors will be perfectly happy because they receive the web page resources they expect. However, Googlebot, Google’s web page crawler, will spider through your site including the RSS feed locations. Remember, the RSS feed folders will contain an index.xml. XML files are not normally a default directory index resource for most web hosts. Since there is no index.html file in the feed folder, the web server thinks it’s being asked to deliver a file listing. Again remember that file listings are disabled by most web hosts for security. Thus you get the error:
Access Forbidden (403)
You are forbidden by the web server to access that folder listing.
How to fix the Access Forbidden (403) error
Now that we know exactly why we get this error we attempt a fix. If your host runs Apache, the solution will likely be simple. Edit or create the .htaccess file in the root of your site and add index.xml to the list of directory index resources. For example, if it not already there, add the following line somewhere near the top of the file:
DirectoryIndex index.html index.php index.xml
The index.xml in the list will tell Apache to serve the XML file when Googlebot requests the RSS feed directory. While you’re doing this, inspect a few o the feed directories to make sure the index.xml files have the correct permissions (usually 775 for most server setups) and the correct ownership. The ownership settings should be:
-
useris the user account with root privileges on your web server. -
groupis usuallywww-dataorapachebut you may need to check this with your hosting provider.
You can test your changes by pointing your browser to a few feed directories to see if the server returns XML. Remember to leave out the index.xml file and specify the directory only. For example:https://example.com/your-post/feed/
If your browser displays the RSS feed XML, you know the problem has been solved and can be reasonably confident that Googlebot won’t encounter the 403 error.
This may not work if you’re running a VPS server for your site where some more in-depth configuration may be needed, such as editing your Apache configuration files. Also, .htaccess is not used by other web servers such as NGINX. In these cases, your next port of call should be to contact your hosting provider. Tell them that you would like to add index.xml to the directory index resources so that the XML file is served when a visitor lands in a directory. Most good hosting companies will be able to guide you on your options or make the change on your behalf. After you’ve applied the fix, be sure to go to your Google Search Console to revalidate the affected page.
Photo by Lucian Alexe on Unsplash
You may also like

Drupal to WordPress Migration Guide
In this guide, you'll find insights drawn from almost 15 years of specialising in complex Drupal to WordPress migration projects. I'll walk you through the entire migration process, from the initial evaluation to post-launch considerations.
Secure Your AI Workflow Using Local Tokenisation
Don't leak confidential client data when using cloud-based LLMs. Secure your AI workflow with local tokenisation using PaigeSafe.

How To Set Up Drupal 7 Docker Containers for Migration Projects
Learn how Docker is a valuable tool for Drupal 7 end of life migrations. In this post, I'll give a step-by-step guide to setting up a Drupal 7 container for your migration project.